Data Warehouses vs Data Lakes
Data Driven

¿Qué distingue a un Data Lake de un Data Warehouse ¿Tengo que elegir entre ellos o necesito ambos? ¿Cuáles son las mejores prácticas actuales para configurar la relación entre un Data Warehouse y un Data Lake ?
Data Warehouse: una definición
En su forma más básica, un almacén de datos es un depósito central para todos los datos que se recopilan en los sistemas comerciales de una organización. Los datos se extraen, transforman y cargan (conocido como ETL) en un almacén de datos, que admite aplicaciones para informes, análisis y extracción de datos en este conjunto de datos extraído y seleccionado . La generación anterior de infraestructura de datos se centró en almacenes de datos y se basó en tecnologías como Teradata, Oracle, Neteeza, Greenplum y Vertica, entre otras.
En el pasado, las empresas tomaban datos sin procesar además de datos procesados; realizar ETL en él utilizando motores como, Informatica y otros; y luego cárguelo en el almacén de datos para que lo consuman los analistas comerciales o los usuarios. Sin embargo, con el aumento de los volúmenes de datos, este enfoque crea dos problemas: primero, los analistas no tienen acceso a los datos sin procesar originales y se limitan a utilizar el subconjunto extraído del almacén de datos; y segundo, solo es posible el procesamiento de datos estructurados en un almacén de datos. No es factible ninguna aplicación o análisis de aprendizaje profundo que utilice información no estructurada. Ambos problemas crean severas limitaciones para hacer que los datos y el procesamiento sean ampliamente accesibles.
En un mundo centrado en el almacén de datos, si la estructura definida de los datos en el almacén no encajaba en su análisis o si deseaba analizar contenido no estructurado, simplemente no tenía suerte. Debería comunicarse con el equipo de datos para realizar su solicitud de datos, esperar hasta que tuviera los conjuntos de datos sin procesar, los procesara y derivara la información y la estructura en la que estaba interesado. Luego, esperó a que el equipo de datos lo cargara en el almacén de datos. Este fue un proceso muy lento.
Este proceso tradicional lo hizo fundamentalmente menos ágil. Después de todo, los analistas comerciales y los usuarios tenían que depender de los profesionales de datos para procesar los datos sin procesar y llevarlos al almacén en la forma deseada (estructurada). En muchos casos, los datos sin procesar originales simplemente se desecharían o archivarían debido a la falta de almacenamiento disponible; no se pudo utilizar para el análisis o la verificación después de realizar la ETL.
Por todas estas razones y más, poseer solo un almacén de datos en una arquitectura de datos moderna para respaldar una empresa basada en datos simplemente no es óptimo.
¿Qué es un Data Lake?
El término lago de datos (Data Lake) fue acuñado por primera vez por James Dixon, fundador y director de tecnología de Pentaho, en 2010. Dixon postuló que un lago de datos es un depósito de almacenamiento que contiene una gran cantidad de datos sin procesar en su formato nativo hasta que se necesitan.
Los lagos de datos abordan las deficiencias de los almacenes de datos de dos maneras. En primer lugar, en los lagos de datos, los datos se pueden almacenar en formatos estructurados, semiestructurados o no estructurados. En segundo lugar, el esquema de datos se decide al leer, en lugar de cargar o escribir los datos. Por lo tanto, siempre puede cambiar el esquema si hay información adicional o estructuras que necesita de los datos sin procesar, lo que lleva a una mayor agilidad organizacional. Esto también significa que los datos están disponibles rápidamente porque no es necesario seleccionarlos antes de que puedan ser consumidos por los motores de procesamiento.
Debido a la rentabilidad de los lagos de datos, nunca hay necesidad de desechar o archivar los datos sin procesar. Siempre está allí si alguno de sus usuarios desea volver a visitarlo.
Todos estos puntos (almacenamiento rentable de todo el contenido, diferentes tipos de capacidades de procesamiento en datos estructurados y no estructurados, disponibilidad rápida de datos, agilidad y flexibilidad) son esenciales a medida que las organizaciones avanzan hacia una infraestructura de datos de autoservicio.
Diferencias clave entre lagos de datos y almacenes de datos
Cada vez más empresas están aumentando sus almacenes de datos con lagos de datos para hacer que sus macrodatos sean verdaderamente de autoservicio.
Hay ocho diferencias básicas entre los lagos de datos y los almacenes de datos. Aquí están los más importantes entre ellos:
- El tipo de datos que van en ellos.
- Cuánto procesamiento experimentan los datos durante la ingestión
- ¿Cuántos tipos diferentes de procesamiento se pueden hacer con estos datos?
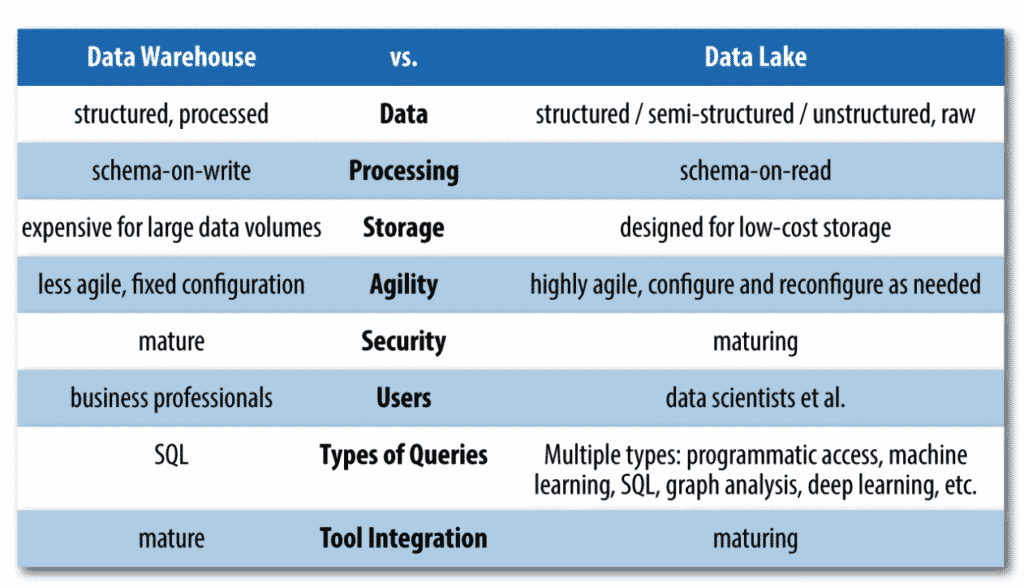
Los almacenes de datos continúan siendo populares porque son tecnologías muy maduras que existen desde la década de 1990. Además, funcionan bien con las herramientas a las que los analistas de negocios y los usuarios se han acostumbrado cuando usan tableros u otros tipos de mecanismos a través de los cuales pueden obtener información de los datos residentes. De hecho, para ciertos casos de uso, los almacenes de datos funcionan muy bien porque los datos están completamente seleccionados y estructurados para responder rápidamente a ciertos patrones de consulta.
Como resultado, los almacenes de datos continúan dominando la mayoría de las organizaciones. Pero cada vez más empresas se encuentran con los obstáculos que mencionamos anteriormente. Para superarlos, están aumentando sus almacenes de datos con lagos de datos para hacer que su big data sea verdaderamente de autoservicio. En muchos casos, el lago puede servir como área de preparación para el almacén de datos, que luego actúa como los datos más seleccionados para ser analizados.
Artículos relacionados
Descubre los cientos de artículos en nuestro blog